pacman::p_load(tidyverse, seriation,
dendextend, heatmaply)Hands-on Exercise 5C
14 Heatmap for Visualising and Analysing Multivariate Data
14.1 Overview and Learning Outcomes
This hands-on exercise is based on Chapter 14 of the R for Visual Analytics book.
Heatmaps visualise data through variations in colouring. When applied to a tabular format, heatmaps are useful for cross-examining multivariate data, through placing variables in the columns and observations in the rows and colouring the cells within the table.
Heatmaps are good for showing variance across multiple variables, revealing any patterns, displaying whether any variables are similar to each other, and for detecting any correlations that exist between them.
The learning outcome is to plot static and interactive heatmaps for visualising and analysing multivariate data.
14.2 Getting Started
14.2.1 Installing and Loading Required Libraries
In this hands-on exercise, the following R packages are used:
tidyverse (i.e. readr, tidyr, dplyr) for performing data science tasks such as importing, tidying, and wrangling data;
seriation for ordering objects;
dendextend for extending dendrogram objects to visualise and compare trees of hierarchical clusterings; and
heatmaply for plotting interactive heatmaps.
The code chunk below uses the p_load() function in the pacman package to check if the packages are installed. If yes, they are then loaded into the R environment. If no, they are installed, then loaded into the R environment.
14.2.2 Importing Data
The dataset for this hands-on exercise is imported into the R environment using the read_csv() function in the readr package and stored as the R object, wh. The data is from the World Happiness 2018 report.
wh = read_csv("data/WHData-2018.csv")The tibble data frame, wh, has 12 columns and 156 rows. Other than the “Country” and “Region” variables, the remaining variables are continuous numerical data.
14.2.3 Preparing Data and Transforming Data Frame into Matrix
The row names are changed to the country names instead of numbers.
row.names(wh) = wh$CountryThe relevant variables are selected - “Happiness score”, “GDP per capita”, “social support”, “Health life expectancy”, “Freedom to make life choices”, “Generosity”, and “Perceptions of corruption”.
wh1 = select(wh, c(3, 7:12))The data frame is then converted to the data matrix.
wh_matrix = data.matrix(wh)14.3 Creating Static Heatmap
There are many R packages and functions that can be used to drawing static heatmaps, they are:
heatmap()function in the stats package. It draws a simple heatmap.heatmap.2()function in the gplots package. It draws an enhanced heatmap.pheatmap()function in the pheatmap package. The package (also known as Pretty Heatmap) provides functions to draws pretty heatmaps and allows more control to change the appearance of heatmaps.ComplexHeatmap package of R/Bioconductor package. The package draws, annotates and arranges complex heatmaps (very useful for genomic data analysis). The full reference guide of the package is available here.
superheat package: A Graphical Tool for Exploring Complex Datasets Using Heatmaps. A system for generating extendable and customizable heatmaps for exploring complex datasets, including big data and data with multiple data types. The full reference guide of the package is available here.
In this sub-section, the most basic, heatmap() function is used.
14.3.1 Working with R Stats heatmap()
A heatmap is plotted using the heatmap() function in the stats package.
wh_heatmap = heatmap(wh_matrix,
Rowv=NA, Colv=NA)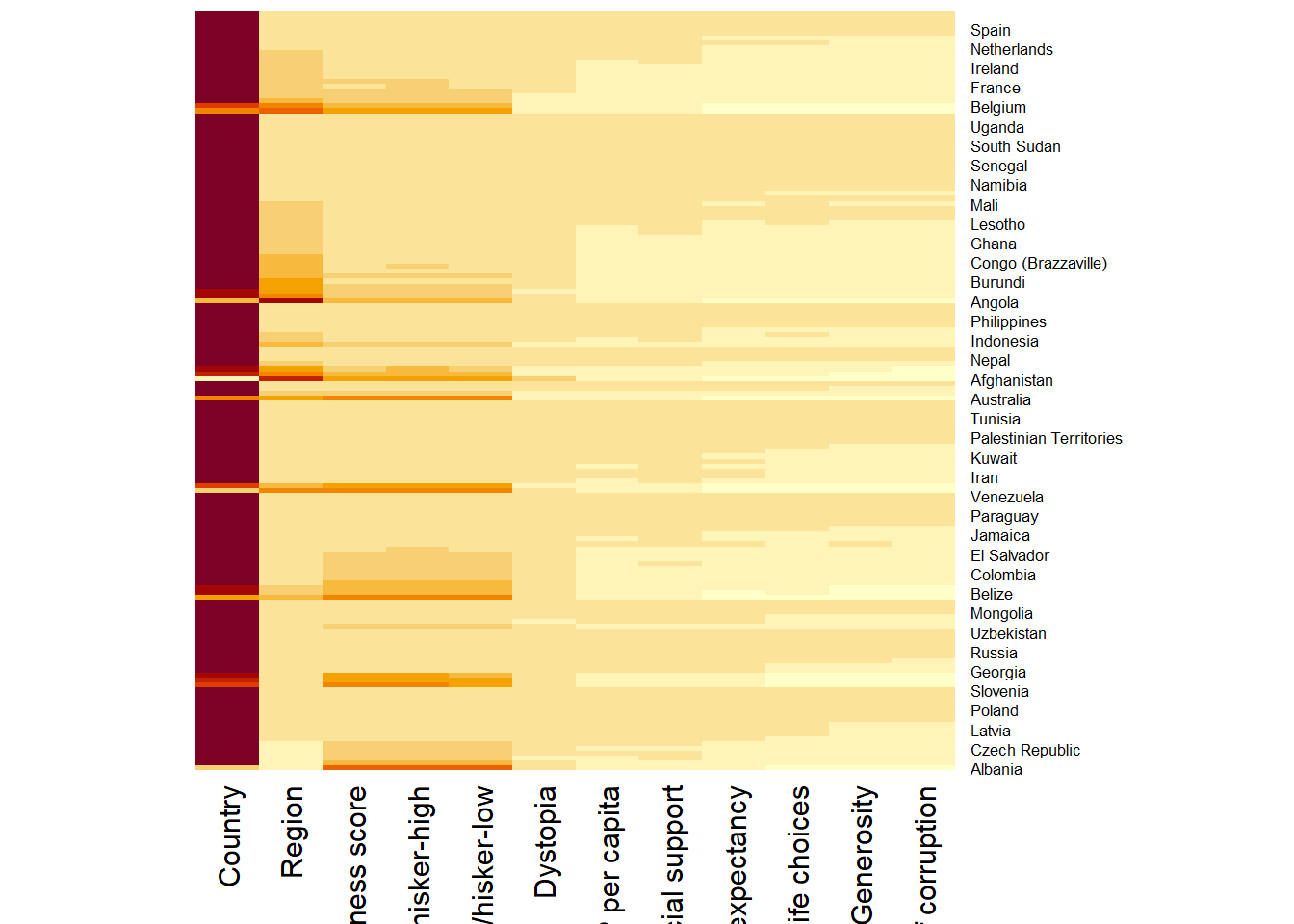
Note: By default, the
heatmap()function plots a cluster heatmap. The arguments “Rowv=NA” and “Colv=NA” are used to switch off the option of plotting the row and column dendrograms.
If the “Rowv” and “Colv” arguments are excluded, the plotted cluster heatmap would show the row and column dendrograms.
wh_heatmap = heatmap(wh_matrix)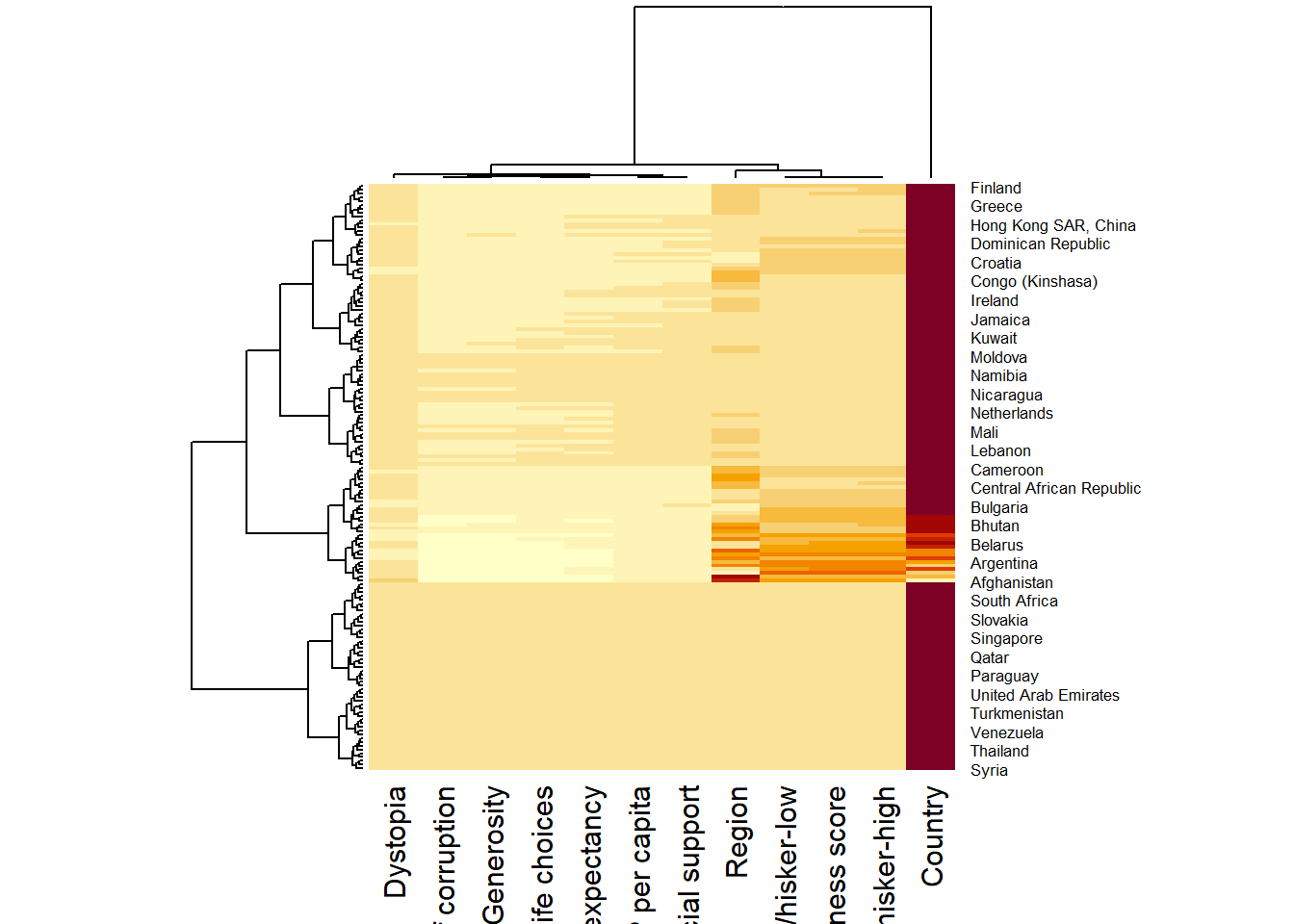
Note: The order of both rows and columns is different compare to the native wh_matrix. This is because the heatmap would do a reordering using clusterisation, i.e., it calculates the distance between each pair of rows and columns and try to order them by similarity. Moreover, the corresponding dendrogram are provided beside the heatmap.
Based on the plot above, the red cells denote small values, and yellow cells denote large ones. This heatmap is not really informative. Indeed, the “Happiness score” variable has relatively higher values, what means that the other variables with small values all look the same. Thus, we need to normalise this matrix. This is done using the “scale” argument. It can be applied to rows or to columns depending on needs.
A heatmap with normalisation column-wise is plotted below.
wh_heatmap = heatmap(wh_matrix,
scale="column",
cexRow = 0.6,
cexCol = 0.8,
margins = c(10, 4))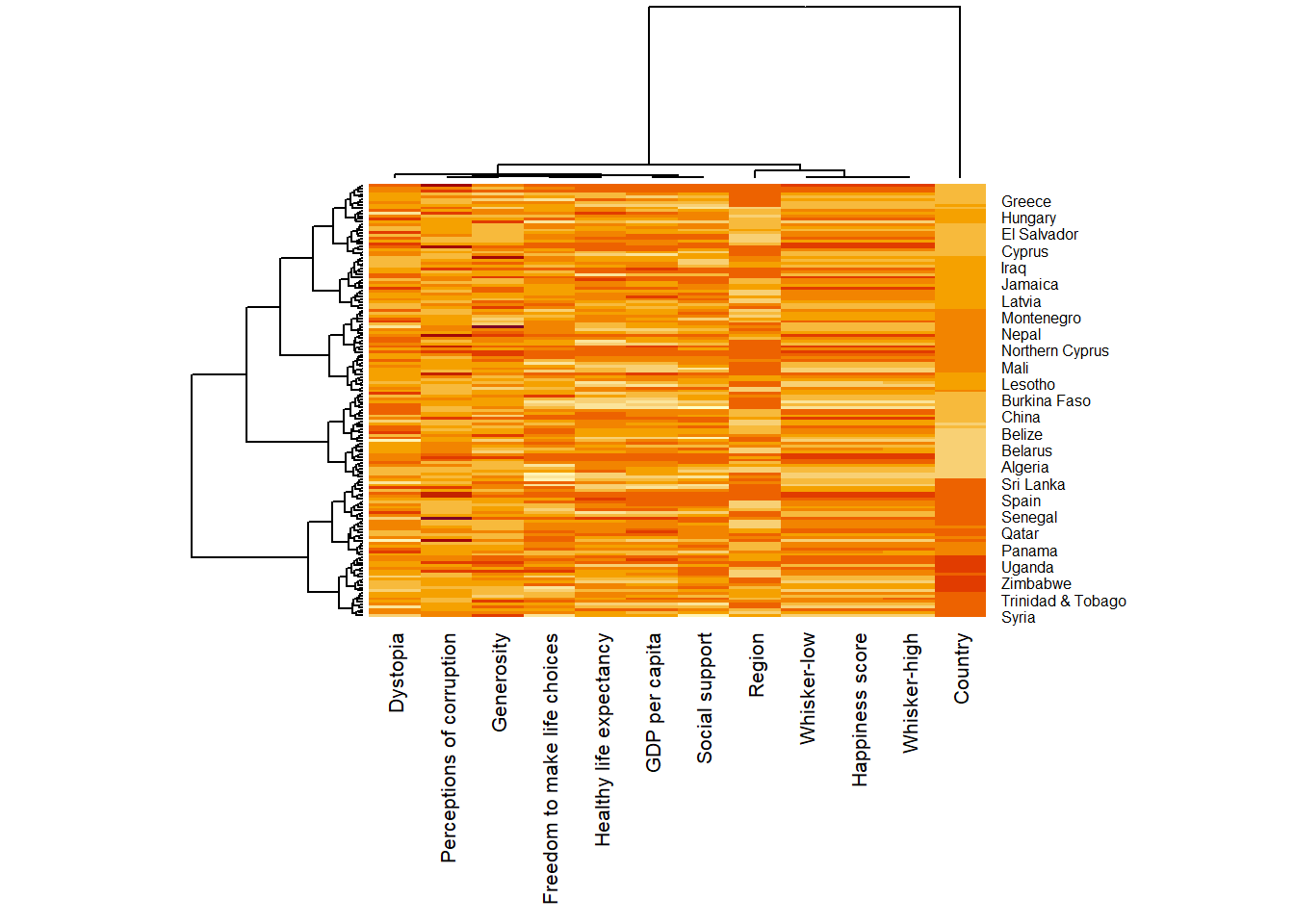
Note: The values are now scaled. Also, the “margins” argument is used to ensure that the entire x-axis labels are displayed completely, and the “cexRow” and “cexCol” arguments are used to define the font size used for the y-axis and x-axis labels respectively.
14.4 Creating Interactive Heatmap
The heatmaply package is for building interactive cluster heatmaps that can be shared online as a stand-alone HTML file. It is designed and maintained by Tal Galili. The Introduction to Heatmaply provides more information on the features and functions of the package.
In this sub-section, the heatmaply package is used to design an interactive cluster heatmap.
14.4.1 Working with heatmaply()
The heatmaply() function is used to plot the interactive heatmap for the wh_matrix.
heatmaply(wh_matrix[, -c(1, 2, 4, 5)])Note:
Different from the
heatmap()function, theheatmaply()function places the default horizontal dendrogram on the right side. On the other hand, the text label of each row is placed on the left side.When the x-axis marker labels are too long, they will be rotated by 135 degree from the north.
14.4.2 Data Transformation
When analysing a multivariate dataset, it is very common that the variables include values that reflect different types of measurement. In general, these variables’ values have their own range. In order to ensure that all the variables have comparable values, data transformation is commonly used before clustering. The three main data transformation methods are supported by the heatmaply() function are: scale, normalise, and percentilse.
14.4.2.1 Scaling Method
When all variables are (or assumed to be) from some normal distribution, then scaling (i.e., subtract the mean and divide by the standard deviation) would bring them all close to the standard normal distribution. In such a case, each value would reflect the distance from the mean in units of standard deviation. The “scale” argument in the heatmaply() function supports column and row scaling.
The plot below uses the “scale” argument to scale column-wise.
heatmaply(wh_matrix[, -c(1, 2, 4, 5)],
scale = "column")The plot below uses the “scale” argument to scale row-wise.
heatmaply(wh_matrix[, -c(1, 2, 4, 5)],
scale = "row")14.4.2.2 Normalising Method
When variables in the dataset comes from possibly different (and non-normal) distributions, the normalise function can be used to bring the values to the 0 to 1 scale by subtracting the minimum and dividing by the maximum of all observations. This preserves the shape of each variable’s distribution while making them easily comparable on the same “scale”. Different from scaling, the normalise method is performed on the input dataset, i.e., wh_matrix.
heatmaply(normalize(wh_matrix[, -c(1, 2, 4, 5)]))14.4.2.3 Percentising Method
This is similar to ranking the variables, but instead of keeping the rank values, they are divided by the maximal rank. This is done by using the ecdf of the variables on their own values, bringing each value to its empirical percentile. The benefit of the percentise method is that each value has a relatively clear interpretation, it is the percent of observations that got that value or below it. Similar to the normalise method, the percentise method is also performed on the input dataset, i.e., wh_matrix.
heatmaply(percentize(wh_matrix[, -c(1, 2, 4, 5)]))14.4.3 Clustering Algorithm
The heatmaply package supports a variety of hierarchical clustering algorithm. The main arguments provided are:
“distfun” is used to compute the distance (dissimilarity) between both rows and columns. Defaults to “dist”. The options “pearson”, “spearman” and “kendall” can be used to use correlation-based clustering, which uses “as.dist(1 - cor(t(x)))” as the distance metric (using the specified correlation method).
“hclustfun” is used to compute the hierarchical clustering when “Rowv” or “Colv” are not dendrograms. Defaults to “hclust”.
“dist_method” default is NULL, which results in “euclidean” being used. It can accept alternative character strings indicating the method to be passed to distfun. By default, “distfun” is “dist””, and hence this can be one of “euclidean”, “maximum”, “manhattan”, “canberra”, “binary” or “minkowski”.
“hclust_method” default is NULL, which results in “complete” method being used. It can accept alternative character strings indicating the method to be passed to “hclustfun”. By default hclustfun is hclust, and hence this can be one of “ward.D”, “ward.D2”, “single”, “complete”, “average” (= UPGMA), “mcquitty” (= WPGMA), “median” (= WPGMC) or “centroid” (= UPGMC).
In general, a clustering model can be calibrated either manually or statistically.
14.4.4 Manual Approach
A heatmap is plotted using a hierarchical clustering algorithm with “dist_method =”euclidean” and “hclust_method =”ward.D”.
heatmaply(normalize(wh_matrix[, -c(1, 2, 4, 5)]),
dist_method = "euclidean",
hclust_method = "ward.D")14.4.5 Statistical Approach
In order to determine the best clustering method and number of clusters, the dend_expend() and find_k() functions in the dendextend package is used.
First, the dend_expend() function is used to determine the recommended clustering method to be used. The output table shows that the “average” method should be used because it gave the highest optimum value.
wh_d = dist(normalize(wh_matrix[, -c(1, 2, 4, 5)]),
method = "euclidean")
dend_expend(wh_d)[[3]] dist_methods hclust_methods optim
1 unknown ward.D 0.6137851
2 unknown ward.D2 0.6289186
3 unknown single 0.4774362
4 unknown complete 0.6434009
5 unknown average 0.6701688
6 unknown mcquitty 0.5020102
7 unknown median 0.5901833
8 unknown centroid 0.6338734Next, the find_k() function is used to determine the optimal number of clusters. The plot shows that k=3 would be good.
wh_clust = hclust(wh_d, method = "average")
num_k = find_k(wh_clust)
plot(num_k)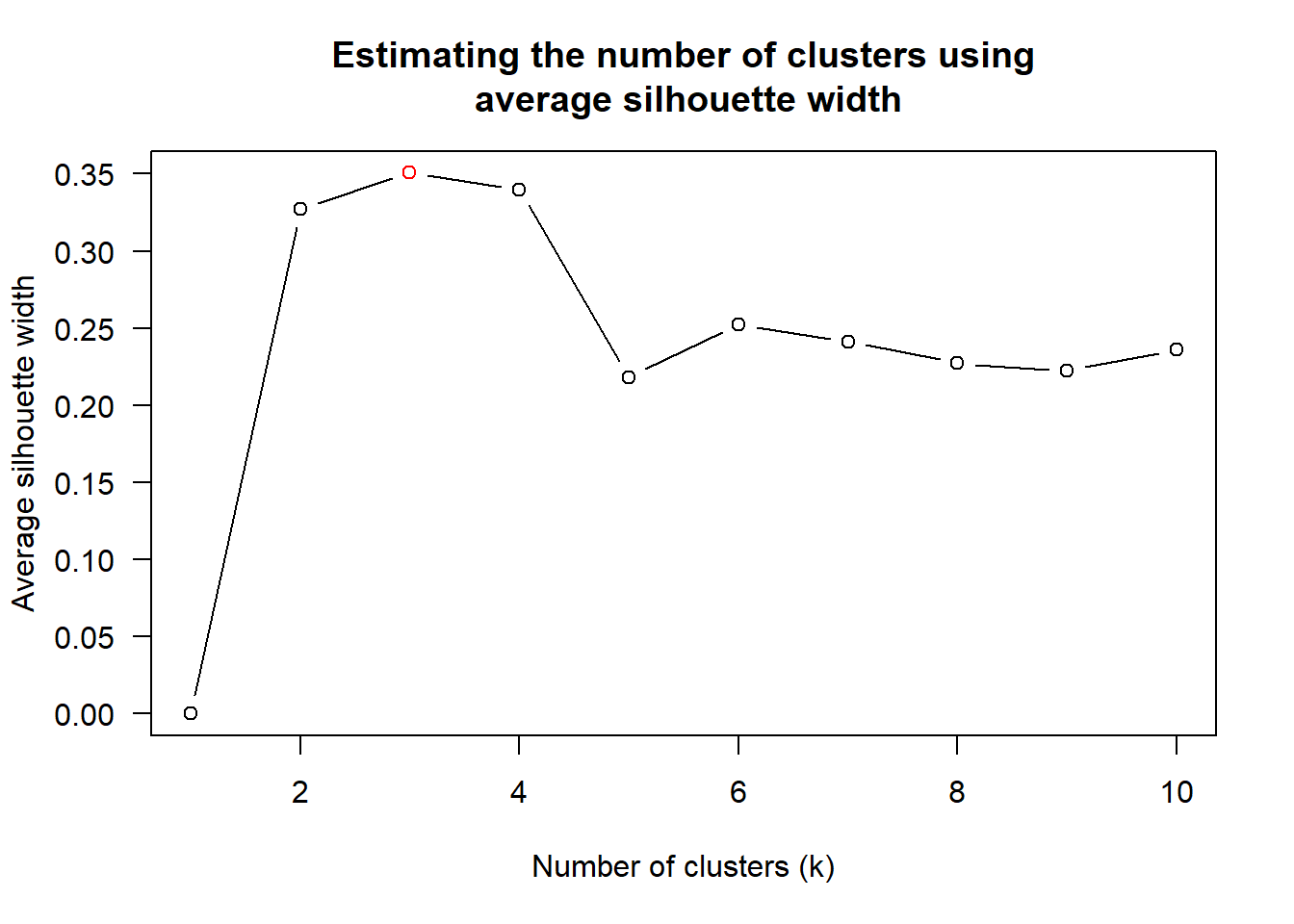
After obtaining the statistical analysis results, the heatmap is plotted.
heatmaply(normalize(wh_matrix[, -c(1, 2, 4, 5)]),
dist_method = "euclidean",
hclust_method = "average",
k_row = 3)14.4.6 Seriation
One of the problems with hierarchical clustering is that it does not actually place the rows in a definite order; it merely constrains the space of possible orderings. For example, take three items A, B and C. If you ignore reflections, there are three possible orderings: ABC, ACB, BAC. If clustering them gives you ((A+B)+C) as a tree, you know that C can’t end up between A and B, but it does not tell you which way to flip the A+B cluster. It doesn’t tell you if the ABC ordering will lead to a clearer-looking heatmap than the BAC ordering.
The heatmaply() function uses the seriation package to find an optimal ordering of rows and columns. Optimal means to optimise the Hamiltonian path length that is restricted by the dendrogram structure. This, in other words, means to rotate the branches so that the sum of distances between each adjacent leaf (label) will be minimized. This is related to a restricted version of the travelling salesman problem.
In the plot below, the seriation algorithm of Optimal Leaf Ordering (OLO) is used. This algorithm starts with the output of an agglomerative clustering algorithm and produces a unique ordering, one that flips the various branches of the dendrogram around so as to minimise the sum of dissimilarities between adjacent leaves.
heatmaply(normalize(wh_matrix[, -c(1, 2, 4, 5)]),
seriate = "OLO")The default option is “OLO” (Optimal leaf ordering) which optimises the above criterion (in O(n^4)). Another option is “GW” (Gruvaeus and Wainer) which aims for the same goal but uses a potentially faster heuristic.
heatmaply(normalize(wh_matrix[, -c(1, 2, 4, 5)]),
seriate = "GW")The option “mean” gives the output we would get by default from heatmap functions in other packages such as gplots::heatmap.2.
heatmaply(normalize(wh_matrix[, -c(1, 2, 4, 5)]),
seriate = "mean")The option “none” gives us dendrograms without any rotation that is based on the data matrix.
heatmaply(normalize(wh_matrix[, -c(1, 2, 4, 5)]),
seriate = "none")14.4.7 Working with Colour Palettes
The default colour palette uses by the heatmaply package is “viridis“. However, users can use other colour palettes to improve the aesthetics and visual friendliness of the heatmap.
In the plot below, the “Blues” colour palette of rColorBrewer is used.
heatmaply(normalize(wh_matrix[, -c(1, 2, 4, 5)]),
seriate = "none",
colors = Blues)14.4.8 Finishing Touch
Besides providing a wide collection of arguments for meeting the statistical analysis needs, the heatmaply package also provides many plotting features to ensure cartographic quality heatmap can be produced.
In the plot below, the following arguments are used:
“k_row” is used to produce 5 groups.
“margins” is used to change the top margin to 60 and row margin to 200.
“fontsizw_row” and “fontsize_col” are used to change the font size for row and column labels to 4.
“main” argument is used to write the main title of the plot.
“xlab” and “ylab” are used to given the x-axis and y-axis labels respectively.
heatmaply(normalize(wh_matrix[, -c(1, 2, 4, 5)]),
Colv=NA,
seriate = "none",
colors = Blues,
k_row = 5,
margins = c(NA,200,60,NA),
fontsize_row = 4,
fontsize_col = 5,
main="World Happiness Score and Variables by Country, 2018 \nDataTransformation using Normalise Method",
xlab = "World Happiness Indicators",
ylab = "World Countries"
)~~~ End of Hands-on Exercise 5C ~~~